
Web Scraping API cost control has become a critical challenge for enterprises that rely on scraping APIs for market data, competitor intelligence, and price monitoring. Many teams see monthly Web Scraping API costs exceed expectations by 10× due to invalid calls, misaligned pricing models, and operational blind spots. If you haven’t chosen a provider yet, start with our Web Scraping API vendor comparison checklist before optimizing cost.This guide breaks down the root causes of Web Scraping API cost overruns and presents production-ready strategies—pricing model selection, the 80/20 value rule, caching, deduplication, and Web Scraping budget governance—to help teams reduce crawler API costs and improve efficiency.
For the foundational crawling workflow (request → parsing → storage → scheduling) behind these costs, see our Web Crawling Basics Guide.
Core Keywords: Web Scraping API cost control, crawler API caching strategy, API deduplication technology, Web Scraping budget governance, crawler API cost reduction tips
I. Why Web Scraping API Cost Control Fails in Production
The uncontrollability of Web Scraping API costs typically comes from four overlapping factors: demand volatility, pricing complexity, anti-crawling impacts, and data redundancy. Therefore, accurate diagnosis is the foundation of Web Scraping API cost control—only then can you apply targeted fixes.
1.1 Demand Volatility + Unrestrained Crawling
Enterprise crawler demands often spike with business events: price monitoring before promotions, competitor tracking after launches, or policy-driven industry aggregation. Meanwhile, some teams pursue “data completeness” with full-scale crawling + high-frequency refresh—for example, crawling static “About Us” pages hourly. As a result, Web Scraping API call volumes surge, and costs follow immediately.
1.2 Complex Pricing Models Hide the Real Cost
Most Web Scraping APIs are not flat-rate. Instead, they stack base fees, feature premiums, and over-quota pricing:
- Billing traps: “successful calls only” claims may still count retries caused by anti-bot failures.
- Feature premiums: dynamic rendering, overseas proxies, or advanced parsing may be enabled by default, adding 50%–200%.
- Tiered price increases: unit cost rises sharply once you exceed the base quota.
Because these costs compound, real spend often exceeds the budget and becomes a key barrier to Web Scraping API cost control.
1.3 Anti-Crawling Mechanisms Create Paid Failures
Target websites deploy IP bans, CAPTCHAs, and rate limits. Even worse, many vendors still charge for failed calls. For example, if success rate drops from 95% to 30%, you may need 3× call volume to get the same valid data—effectively paying 3× per usable record.In addition, responsible Web Scraping API cost control requires respecting website access policies such as robots.txt, which defines permissible crawling behavior at the protocol level.
1.4 Data Duplication and Redundancy Waste 30%–60%
Without deduplication, duplicate URL crawling across teams, inconsistent keyword inputs (“mobile phone” vs “smartphone”), and blind retries can waste 30%–60% of total calls. Notably, this is also the easiest waste source to fix in Web Scraping API cost control.
II. Web Scraping API Pricing Models for Cost Control: Per-Request vs Subscription vs Hybrid
Choosing the right model is the foundation of Web Scraping API cost control. Otherwise, the wrong plan can double spend.
If you’re still choosing a provider, our vendor comparison helps you evaluate pricing, reliability, and feature premiums before you commit.
2.1 Per-Request Billing (Flexible, Needs Strong Guardrails)
Logic: pay per call; unit price may drop with tiers.
Best for: volatile, ad-hoc workloads (10k–1M calls/month).
Risk: spend explodes when volume spikes.
Controls: set daily/weekly caps, add caching + deduplication, and prefer “successful calls only” plans when reliable.
2.2 Subscription Billing (Predictable, Watch Quota Waste)
Logic: fixed fee for fixed quota; overages cost more or suspend service.
Best for: stable workloads with ≤20% volatility (e.g., daily price monitoring).
Risk: quota waste (using 50% of quota = overpaying 50%).
Controls: size plans from historical data; use per-request for small bursts instead of upgrading tiers.
2.3 Hybrid Model (Often Best for Enterprises)
Logic: base fee + base quota + cheaper per-request overage.
Best for: stable baseline plus periodic spikes (promotions, events).
Controls: set base quota to cover ~80% of normal demand; monitor overage tiers and plan for spikes.
2.4 Pricing Model Selection Matrix
| Core Business Characteristics | Recommended Pricing Model | Key Web Scraping API Cost Control Actions |
|---|---|---|
| Short-term projects, highly volatile volumes | Per-Request | Caps + caching + deduplication |
| Long-term, stable volumes (≤20% fluctuation) | Subscription | Right-size quota + scalable plans |
| Long-term + periodic spikes | Hybrid | Base quota ≈ 80% baseline + control overages |
III. The 80/20 Rule for Web Scraping API Cost Control
In Web Scraping API cost control, the 80/20 rule is practical: 80% of value often comes from 20% of requests, while low-value requests burn the budget.
3.1 Identify High-Value vs Low-Value Requests
High-Value (Prioritize quota and freshness)
- Core business data (core category prices, competitor launches, industry policies).
- High-timeliness data (inventory, limited-time promotions, hot topics).
- Irreplaceable data (niche vertical data with no alternatives).
Low-Value (Reduce or redesign)
- Static pages (About pages, definitions).
- Redundant variants (keyword synonyms, duplicate URLs).
- Low-relevance data (non-target regions, marginal categories).
3.2 80/20 Cost Control Actions
- Quota tilting: 80% quota to 20% core requests; low-value ≤10%.
- Differentiated frequency: core data hourly; static data monthly or cached long-term.
- Tiered storage: high-value via API; low-value via free crawlers or cheaper sources.
To fully understand pricing models, start with our complete Web Scraping API overview.
IV. Web Scraping API Cost Control with Caching: TTL by Keyword/URL/Page Type
Caching is the fastest lever for Web Scraping API cost control. Instead of repeating paid calls, store responses (Redis/Memcached) and serve identical requests from cache.
4.1 Caching Architecture (3 Layers)
- Application-layer cache: local memory/files for high-frequency small workloads.
- Middleware cache: Redis Cluster for shared teams and large-scale traffic, commonly used for response caching, TTL control, and Bloom Filter–based deduplication.
- API-layer cache: vendor-provided caching when available.
Core logic: hash request parameters (URL/keyword/rendering/location) → check cache → return if valid → otherwise call API and update cache.
4.2 TTL Customization (The Core of Precise Cost Control)
4.2.1 TTL by Keyword
- Core keywords (e.g., “iPhone 15 price”): TTL 1–6 hours
- Regular keywords (e.g., “smartphone review”): TTL 12–24 hours
- Long-tail: TTL 7–14 days
- Static: TTL 30+ days or permanent
4.2.2 TTL by URL
- Dynamic URLs (product/news): TTL 0.5–6 hours
- Semi-static (blogs/reports): TTL 24–72 hours
- Static (homepage/about): TTL 7–30 days
- Archived: TTL 90+ days or permanent
4.2.3 TTL by Page Type (Batch Policy)
| Page Type | Update Frequency | Recommended TTL | Applicable Scenarios |
|---|---|---|---|
| E-commerce product page | High | 1–6 hours | price/inventory monitoring |
| News/information page | High | 0.5–2 hours | hot topics, sentiment |
| Industry report page | Low | 7–30 days | trend analysis |
| Corporate official site | Very low | 30–90 days | company info |
| Social media dynamic page | Very high | 10–30 minutes | hot topics, sentiment |
4.3 Advanced Caching Optimizations
- Warm-up: prefill core URLs before peak periods.
- Negative caching: cache invalid URLs briefly (e.g., 5 minutes) to prevent repeated checks.
- Selective invalidation: invalidate cache on known updates; otherwise rely on TTL.
- Namespace isolation: e.g., teamA:product:123 to prevent key collisions.
V. Web Scraping API Cost Control with Deduplication: Standardization + Bloom Filter
Besides caching and deduplication, request mechanics also matter for Web Scraping API cost control. At a minimum, teams should understand HTTP request and response semantics, including methods, status codes, and retry behavior, as defined in the official HTTP specification.
5.1 Keyword Standardization (Semantic Deduplication)
5.1.1 Basic Format Unification
- Case normalization
- Chinese-English normalization
- Remove noise symbols/spaces/emojis
- Simplified/Traditional normalization (as applicable)
5.1.2 Remove Low-Value Modifiers
“latest / popular / recommended / comprehensive” often don’t change core intent:
- “Latest mobile phone price” → “mobile phone price”
5.1.3 Semantic Normalization
- Synonym replacement via dictionary
- Core term extraction (jieba/HanLP)
- Word order normalization
5.1.4 Validate Effectiveness (Similarity ≥80%)
Compare results before/after standardization; if similarity stays high, standardization is safe and prevents duplicate spend.
5.2 Bloom Filter (Exact Deduplication at Scale)
Bloom Filter is ideal for “have we seen this request?” checks at million-scale with low memory.
5.2.1 Core Principles
- Bit array + k hash functions
- Add request → set k bits
- Check request → if any bit is 0 → definitely new; if all 1 → maybe seen
- No deletions; best for daily windows or one-time crawling
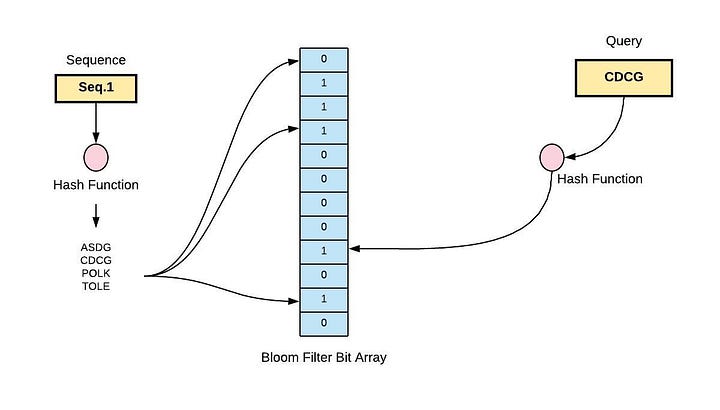
5.2.2 Practical Implementation (Key for Web Scraping API Cost Control)
- Use cases: URL dedup, standardized keyword dedup, URL + time range dedup
- Parameter config (false positive ≤0.1%)
- Deployment: small scale → pybloom_live; large scale → RedisBloom
- False positives: verify via cache; if cache miss → treat as false positive and call API
- Regular reset: daily reset for time-sensitive workloads
5.2.3 Deduplication Targets
Aim for invalid requests ≤10% and track:
- Dedup rate
- Semantic duplication rate
- Exact duplication rate
Case: 1M daily requests → after standardization + Bloom Filter → 550k requests (45% reduction), cutting costs by ~45%.
5.2.4 Bloom Filter Python Example (cleaned)
import math
import hashlib
from bitarray import bitarray
class BloomFilter:
def __init__(self, expected_elements: int, false_positive_rate: float = 0.01):
self.false_positive_rate = false_positive_rate
self.expected_elements = expected_elements
self.bit_array_size = self._optimal_bit_size()
self.hash_func_count = self._optimal_hash_count()
self.bit_array = bitarray(self.bit_array_size)
self.bit_array.setall(0)
self.added_elements = 0
def _optimal_bit_size(self) -> int:
m = - (self.expected_elements * math.log(self.false_positive_rate)) / (math.log(2) ** 2)
return int(math.ceil(m))
def _optimal_hash_count(self) -> int:
k = (self.bit_array_size / self.expected_elements) * math.log(2)
return int(math.ceil(k))
def _hashes(self, element: str) -> list[int]:
data = element.encode("utf-8")
digest = hashlib.md5(data).digest()
indices = []
for i in range(self.hash_func_count):
# Derive indices by slicing and re-hashing (simple, practical)
h = hashlib.md5(digest + i.to_bytes(2, "big")).digest()
idx = int.from_bytes(h, "big") % self.bit_array_size
indices.append(idx)
return indices
def add(self, element: str):
for idx in self._hashes(element):
self.bit_array[idx] = 1
self.added_elements += 1
def contains(self, element: str) -> bool:
return all(self.bit_array[idx] for idx in self._hashes(element))
def stats(self) -> dict:
theoretical_fp = (1 - math.exp(-self.hash_func_count * self.added_elements / self.bit_array_size)) ** self.hash_func_count
return {
"Expected Elements": self.expected_elements,
"Actual Added Elements": self.added_elements,
"Bit Array Size (bits)": self.bit_array_size,
"Hash Functions": self.hash_func_count,
"Expected False Positive Rate": self.false_positive_rate,
"Theoretical FP Rate": theoretical_fp,
}Learn more about Bloom filters:
Bloom Filter for Web Scraping Deduplication: Principle, Python, and Redis
VI. Request Batching and Queue Management for Web Scraping API Cost Control
Besides caching and deduplication, request mechanics also matter for Web Scraping API cost control. In particular, batching reduces call counts, while queueing prevents peak bursts and wasteful retries.
6.1 Request Batching (Reduce Unit Cost by 20%+)
Many providers discount batch calls (e.g., 100 URLs per request).
Batch size tips:
- Follow vendor limits (≤100/≤500)
- Tier by value: 20–50 for high-value; 100–200 for low-value
- Test success rate vs unit cost to find the best batch size
Failure handling:
- full batch fail → retry ≤3 with backoff, then alert
- partial fail → split into smaller batches and retry
6.2 Queue Management (Smooth Peaks)
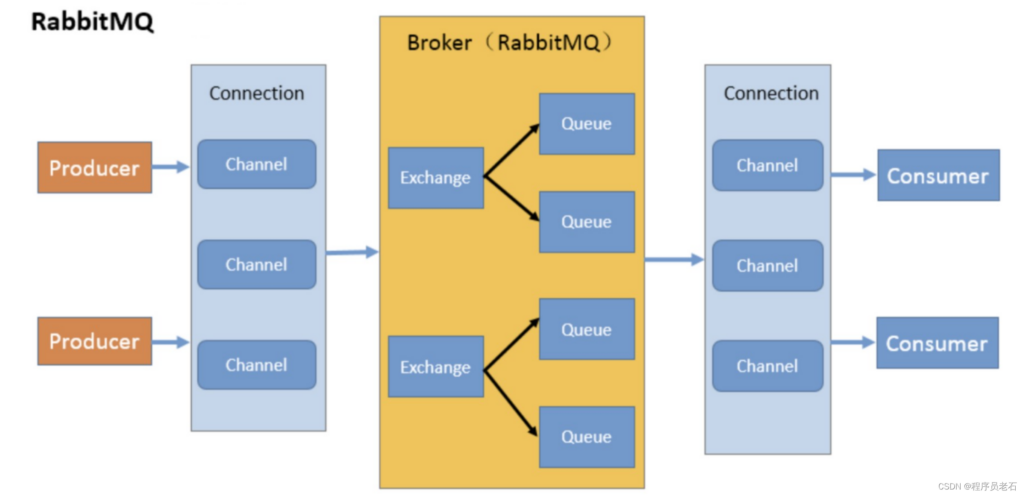
Queueing prevents triggering rate limits and expensive failures.
RabbitMQ overview (internal):
RabbitMQ Advanced Architecture Explained
VII. Rate Limiting and Backoff for Web Scraping API Cost Control
Rate limiting protects you from provider quotas; backoff prevents retry storms. Together, they strengthen crawler API cost reduction tips in production.
Example (public endpoint) uses httpbin for safe testing:
VIII. Monitoring and Budget Governance for Web Scraping API Cost Control
Monitoring is the operational core of Web Scraping budget governance: visualize call volume, spend, and quality metrics so you can stop losses early.
Grafana deployment (internal):
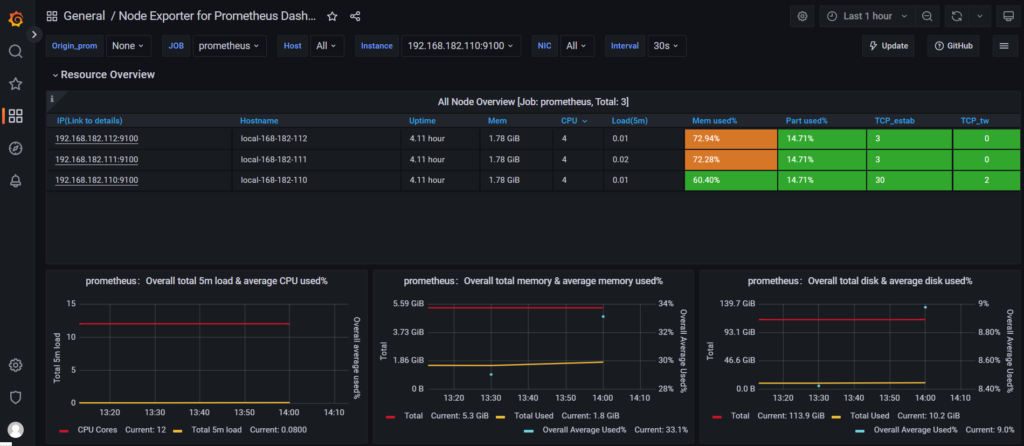
Key alert rules:
- daily/monthly spend hits 80% (warn) / 100% (throttle)
- success rate < 90%
- cache hit rate < 60%
- dedup rate < 20%
- unusual same-URL or off-hours spikes
IX. Web Scraping API Cost Control Checklist
- Pricing model matches workload
- 80/20 request tiering in place
- TTL by keyword/URL/page type; cache hit ≥70%
- Keyword standardization + Bloom filter; dedup ≥30%
- Batching + queueing tuned to limits
- Rate limiting + exponential backoff configured
- Monitoring + alerts live
- Weekly/monthly review of top-cost sources and parameter tuning
X. Conclusion: The Core Logic of Web Scraping API Cost Control
The core of Web Scraping API cost control is not simply “reduce calls,” but achieve minimum cost + maximum value through request value screening, caching + deduplication, efficient scheduling, and real-time monitoring.
In practice, most teams can cut costs by 30%–60% by implementing caching and deduplication first, then improving batching, rate limiting, and dashboards to form an end-to-end budget governance system.
You can also compare vendors to see how different production web scraping API providers structure their billing.
Related Guides
If you’re new to the topic, start with our complete Web Scraping API guide for definitions, use cases, and key concepts.To avoid hidden charges (failed-call billing, rendering premiums, over-quota tiers), use our vendor comparison checklist before you commit.
- What is a Web Scraping API? A Complete Guide for Developers
- Web Crawling & Data Collection Basics Guide
- Bloom Filter for Web Scraping Deduplication: Principle, Python, and Redis
- RabbitMQ Advanced Architecture Explained
- Python Crawler: From InfluxDB to Grafana Visualization, Stock Data Visualization and Alert Notifications
- In-Memory Message Queue with Redis
- RabbitMQ Producer Consumer Model Explained
- Apache Kafka Explained: Architecture, Usage, and Use Cases
- Web Crawling Basics GuideAttachment.tiff
- Web Scraping API Vendor ComparisonAttachment.tiff