In the article [From Basics to Advanced – The Complete Producer-Consumer Model Guide](https://xx/From Basics to Advanced – The Complete Producer-Consumer Model Guide), we introduced the producer-consumer model and summarized several implementation strategies. One of the mentioned optimizations involves using a ring buffer for the queue, but no actual implementation was provided. In this article, we’ll explore how to use a ring buffer to boost the performance of the producer-consumer model under high concurrency.
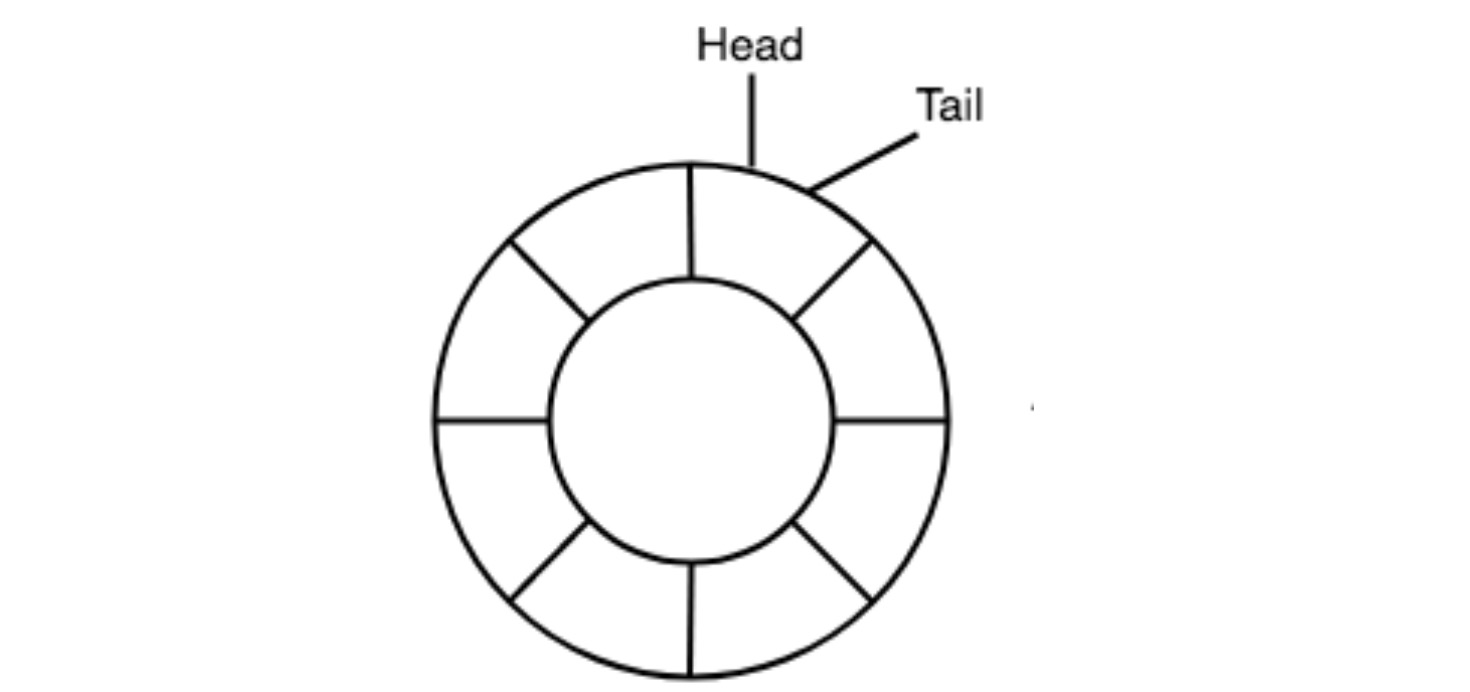
What Is a Ring Buffer?
A ring buffer is a fixed-size, circular data structure. Its core principles are:
- A fixed-size array to avoid frequent memory allocation
- Two pointers: one for writing and one for reading, efficiently tracking positions
- A logic to determine whether the buffer is full or empty
Implementing a Ring Buffer in Rust
Based on the above concepts, here is the definition of a RingBuffer structure:
struct RingBuffer<T> {
buffer: Vec<Option<T>>,
capacity: usize,
head: usize,
tail: usize,
// size: usize,
}bufferstores the contents usingOptionto avoid uninitialized values.headis the write pointer,tailis the read pointer.- When
head == tail, it can mean either full or empty, so we could also add asizefield for clarity.
Here is a more complete implementation:
use std::sync::atomic::{AtomicUsize, Ordering};
use std::cell::UnsafeCell;
pub struct RingBuffer<T> {
buffer: Vec<UnsafeCell<Option<T>>>,
capacity: usize,
head: AtomicUsize,
tail: AtomicUsize,
}
unsafe impl<T: Send> Send for RingBuffer<T> {}
unsafe impl<T: Send> Sync for RingBuffer<T> {}
impl<T> RingBuffer<T> {
pub fn new(capacity: usize) -> Self {
let buffer = (0..capacity)
.map(|_| UnsafeCell::new(None))
.collect();
Self {
buffer,
capacity,
head: AtomicUsize::new(0),
tail: AtomicUsize::new(0),
}
}
pub fn push(&self, value: T) -> Result<(), T> {
let head = self.head.load(Ordering::Relaxed);
let next = (head + 1) % self.capacity;
if next == self.tail.load(Ordering::Acquire) {
return Err(value); // buffer full
}
unsafe {
*self.buffer[head].get() = Some(value);
}
self.head.store(next, Ordering::Release);
Ok(())
}
pub fn pop(&self) -> Option<T> {
let tail = self.tail.load(Ordering::Relaxed);
if tail == self.head.load(Ordering::Acquire) {
return None; // buffer empty
}
let value = unsafe {
(*self.buffer[tail].get()).take()
};
self.tail.store((tail + 1) % self.capacity, Ordering::Release);
value
}
}Compared to the earlier definition, this version introduces UnsafeCell and AtomicUsize. UnsafeCell allows mutation of its contents without requiring a mutable reference, bypassing Rust’s borrow checker. AtomicUsize enables atomic operations for thread safety.
Optimized Single Producer-Consumer Example
Using the RingBuffer implementation above, here’s how to build a simple single-producer single-consumer example:
fn main() {
let buffer = Arc::new(RingBuffer::new(1024));
let producer = {
let buffer = Arc::clone(&buffer);
thread::spawn(move || {
for i in 0..10_000 {
loop {
if buffer.push(i).is_ok() {
break;
}
thread::yield_now();
}
}
})
};
let consumer = {
let buffer = Arc::clone(&buffer);
thread::spawn(move || {
let mut received = 0;
while received < 10_000 {
if let Some(data) = buffer.pop() {
println!("Got: {}", data);
received += 1;
} else {
thread::yield_now();
}
}
})
};
producer.join().unwrap();
consumer.join().unwrap();
}To avoid busy waiting, thread::yield_now() is used to yield control when the buffer is full or empty.
Thread-Safe Multi-Producer Multi-Consumer Implementation
Using Locks
In a multi-threaded context with multiple producers and consumers, we need synchronization to avoid concurrent access to the same slot:
type SharedRingBuffer<T> = Arc<(Mutex<RingBuffer<T>>, Condvar, Condvar)>;
fn main() {
const CAPACITY: usize = 8;
const PRODUCE_COUNT: usize = 30;
let shared: SharedRingBuffer<i32> = Arc::new((
Mutex::new(RingBuffer::new(CAPACITY)),
Condvar::new(),
Condvar::new(),
));
let producer_shared = Arc::clone(&shared);
let producer = thread::spawn(move || {
for i in 0..PRODUCE_COUNT {
let (lock, not_empty, not_full) = &*producer_shared;
let mut rb = lock.lock().unwrap();
while rb.size == rb.capacity {
rb = not_full.wait(rb).unwrap();
}
rb.push(i).unwrap();
println!("[Producer] -> {}", i);
not_empty.notify_one();
}
});
let consumer_shared = Arc::clone(&shared);
let consumer = thread::spawn(move || {
for _ in 0..PRODUCE_COUNT {
let (lock, not_empty, not_full) = &*consumer_shared;
let mut rb = lock.lock().unwrap();
while rb.size == 0 {
rb = not_empty.wait(rb).unwrap();
}
if let Some(item) = rb.pop() {
println!("[Consumer] <- {}", item);
}
not_full.notify_one();
}
});
producer.join().unwrap();
consumer.join().unwrap();
}Lock-Free Queue with CAS
For higher performance, we can use a lock-free queue using Compare-And-Swap (CAS). The crossbeam crate provides a ArrayQueue based on this approach:
use crossbeam::queue::ArrayQueue;
use std::sync::Arc;
use std::thread;
fn main() {
let queue = Arc::new(ArrayQueue::new(1024));
let producers: Vec<_> = (0..4).map(|i| {
let q = queue.clone();
thread::spawn(move || {
for j in 0..500 {
while q.push((i, j)).is_err() {}
}
})
}).collect();
let consumers: Vec<_> = (0..2).map(|i| {
let q = queue.clone();
thread::spawn(move || {
let mut count = 0;
loop {
if let Ok((pid, data)) = q.pop() {
println!("Consumer {} got data from producer {}: {}", i, pid, data);
count += 1;
}
if count >= 1000 {
break;
}
}
})
}).collect();
for p in producers { p.join().unwrap(); }
for c in consumers { c.join().unwrap(); }
}Conclusion
This article builds on [From Basics to Advanced – The Complete Producer-Consumer Model Guide](https://xx/From Basics to Advanced – The Complete Producer-Consumer Model Guide) and dives deeper into using a ring buffer to optimize the producer-consumer model.
We began by introducing the ring buffer concept, implemented a lock-free and atomic version of it, and used it in a single-producer-single-consumer model. Then, we extended this to support multi-producer-multi-consumer setups using two approaches: one with traditional locking and another using crossbeam’s CAS-based lock-free queue.
Of course, building a high-performance producer-consumer model involves many additional optimizations. As discussed in [Functional Extensions of the Producer-Consumer Model](https://xx/Functional Extensions of the Producer-Consumer Model), this model has a wide range of applications. Thus, mastering how to build a robust and high-throughput producer-consumer model is critical.
In upcoming articles, we’ll dive into industry-grade implementations such as Kafka and RabbitMQ, and analyze what makes them performant and scalable.