
In the previous article, [Big Data Query:Turning Data into Decisions](https://xx/Big Data Query:Turning Data into Decisions), we discussed how data only generates value when it is continuously used. During this process, new requirements arise for query capabilities.
In the article [Big Data Query:ClickHouse](https://xx/Big Data Query:ClickHouse), we explored ClickHouse, a performance-focused query engine.
In this chapter, we’ll introduce another performance-oriented engine — Doris.
In real-world production environments, performance is not the only factor that matters. Ease of use and maintainability are equally important in choosing a technical solution.
Enterprises not only expect high performance to support large-scale, fast queries, but also prefer architectures that are simple, low-cost to develop, and easy to maintain.
Doris was born to meet these exact needs. With its minimalist architecture and high-performance real-time querying capabilities, it has quickly become a popular query engine among enterprises.
This article explores Doris from four aspects: technical principles, architecture design, core advantages, and application scenarios.
What Is Doris?
Doris originated from Baidu’s internal project Palo, and was later donated to the Apache Software Foundation, where it successfully graduated as Apache Doris.
It is more than just an OLAP engine — Doris integrates data lake capabilities and real-time analytical processing, making it a high-performance, real-time MPP (Massively Parallel Processing) analytical database.
Guided by the principles of extreme speed and minimalist design, Doris stands out for its simple architecture, easy deployment, and strong real-time capabilities, making it suitable for diverse scenarios such as log analysis, BI reporting, user profiling, and monitoring analytics.
Technical Principles
Doris is designed to support both high-throughput real-time ingestion and sub-second multi-dimensional querying within a single system. Achieving this balance requires multiple technologies working together. Its core technical principles include:
- Columnar Storage
Like other analytical databases, Doris uses column-oriented storage, which stores data from the same column together. This allows only the required columns to be read during queries, dramatically reducing I/O costs and improving efficiency for large-scale analytical workloads. - Vectorized Execution
Vectorized execution leverages CPU SIMD (Single Instruction, Multiple Data) instructions to perform batch operations.
Since version 1.2, Doris has fully adopted a vectorized execution engine, allowing it to process multiple rows simultaneously, greatly accelerating query execution. - Primary Key and Aggregation Models
Doris supports multiple table models to meet different storage and query requirements, enabling both detailed analysis and real-time metric aggregation:- Duplicate Key – Stores all rows (like no-primary-key mode in RDBMS). Ideal for raw log data.
- Aggregate Key – Aggregates rows with the same key. Suitable for analytical summaries.
- Unique Key – Maintains unique keys, allowing updates by primary key. Ideal for real-time data synchronization.
- Real-Time Ingestion
Unlike traditional OLAP systems, Doris supports high-concurrency real-time ingestion and offers various ingestion methods — including Kafka streaming, Flink integration, and HTTP API ingestion. - Flexible Storage
Doris supports both co-located storage and compute (to minimize data transfer overhead) and storage-compute separation, which reduces storage costs while maintaining query efficiency.
Architecture Design
Doris adopts a minimalist MPP architecture, consisting of two core components: FE (Frontend) and BE (Backend).
- FE (Frontend) – Handles client requests, query parsing and optimization, metadata management, and node coordination.
- BE (Backend) – Responsible for data storage and query execution. Data is divided into shards and replicated across BE nodes, enabling parallel processing during queries.
Its architecture is illustrated below:
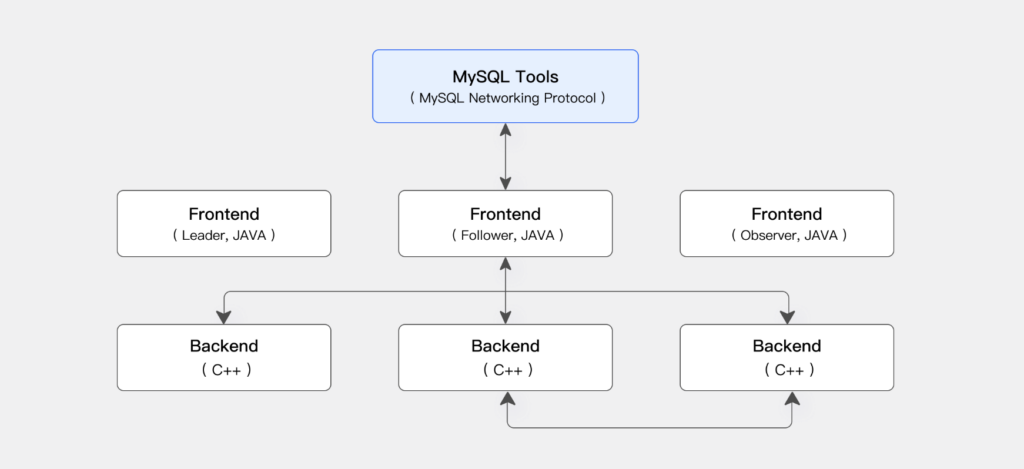
This design is simple yet powerful, with notable characteristics:
- High Parallelism – Each BE node computes independently, with results aggregated by the FE.
- Horizontal Scalability – BE nodes handle both storage and computation, allowing seamless scaling.
- Deployment Independence – No dependency on external systems or frameworks.
Core Advantages
Doris has rapidly become a mainstream big data query engine due to the following advantages:
- Minimalist Architecture – A standalone system with no dependencies on Hadoop, ZooKeeper, or other external components.
- High Performance – Columnar storage combined with vectorized parallel computation enables sub-second responses on datasets with billions of rows.
- Strong Real-Time Capabilities – Multiple ingestion options allow data to become visible within seconds or minutes.
- Ease of Use – Supports the MySQL protocol and standard SQL, making it accessible via any MySQL-compatible client.
- Easy Maintenance – Single, self-contained system design simplifies operations.
- Scalability – Supports horizontal scaling to handle growing data volumes effortlessly.
Application Scenarios
Doris is widely used across industries for various big data analytics use cases, including:
- Real-Time Data Warehouse – Integrate Kafka and Flink for real-time data ingestion and computation with minute-level latency, supporting live dashboards and monitoring.
- User Behavior Analytics – Supports complex, multi-dimensional joins and real-time updates to user attributes and event data.
- BI Reporting – MySQL-compatible, allowing seamless integration with mainstream BI tools for fast, interactive analytics.
- Data Service Layer – Acts as a low-latency data service for upper-layer systems via SQL and MySQL protocol access.
Conclusion
In the evolution of big data query technologies, Doris embodies the concept of stream-batch unification, making real-time data warehousing practical and easy to implement.
With ongoing community development, Doris is also progressing toward lakehouse integration, further expanding its role in the modern data ecosystem.