
Big Data Storage: HDFS
In the previous article, [Deconstructing Big Data:Storage, Computing, and Querying](https://xx/Deconstructing Big Data:Storage, Computing, and Querying), big data technology was deconstructed into three components: storage, computing, and querying.
Among them, storage serves as the foundation of big data, featuring distributed, scalable, and fault-tolerant capabilities, providing reliable large-scale data storage services.
HDFS (Hadoop Distributed File System), as a core component of Hadoop, acts as the distributed storage backbone in the Hadoop ecosystem and is a representative component of big data distributed storage.
This article focuses on HDFS, offering an in-depth look at its design principles, architecture, data storage, performance optimizations, and limitations & challenges to reveal its working mechanisms and technical features.
Design Principles
HDFS, as a component of Hadoop, was designed primarily to meet the needs of large-scale data storage, solving the challenges of reliable persistence and efficient access, and serving as the data layer for MapReduce.
Its design follows several core principles:
- Batch-Oriented – Optimized for write-once, read-many workloads.
- Large File Preference – Designed for storing large files in the GB range; not suitable for small files.
- Sequential Data Access – Supports sequential reads/writes for large files; inefficient for frequent random access.
- High Fault Tolerance – Achieved via multi-replication, with replicas distributed across nodes in different racks to minimize simultaneous failure risk.
- Scalability – Uses a master–slave architecture; capacity can be expanded by adding DataNodes.
- Data Locality – Brings computation closer to where the data resides to reduce network transfer.
Architecture
HDFS adopts a master–slave architecture:
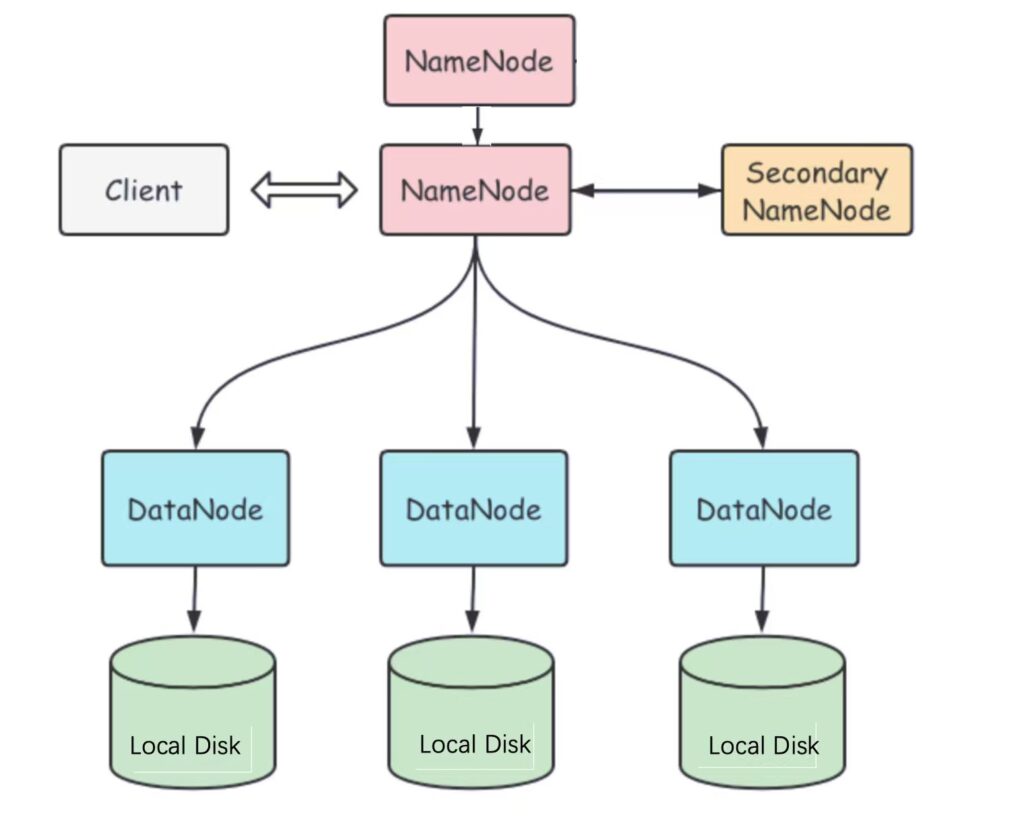
- NameNode – The master node, acting as a central server that manages the file system namespace and client file access. It does not store the file data itself, but records which DataNode holds each data block.
- DataNode – The worker nodes, typically multiple in a cluster, managing the storage on their local machines. They store the actual file blocks and periodically send block reports to the NameNode.
- Client – User applications that interact with NameNode and DataNodes through HDFS APIs or CLI commands for file operations such as upload and download.
As the number of stored files increases, the corresponding metadata in the namespace grows, potentially creating a NameNode bottleneck.
To address this, a Secondary NameNode was introduced to periodically merge the NameNode’s metadata snapshots with its edit logs, preventing excessive log growth.
However, the Secondary NameNode is not a hot standby. If the NameNode fails, the entire cluster becomes unavailable because the Secondary NameNode cannot take over its services.
To improve availability, HDFS now supports active–standby NameNode configurations, where two NameNodes act as hot backups for each other. If the active NameNode fails, the standby immediately takes over and continues service.
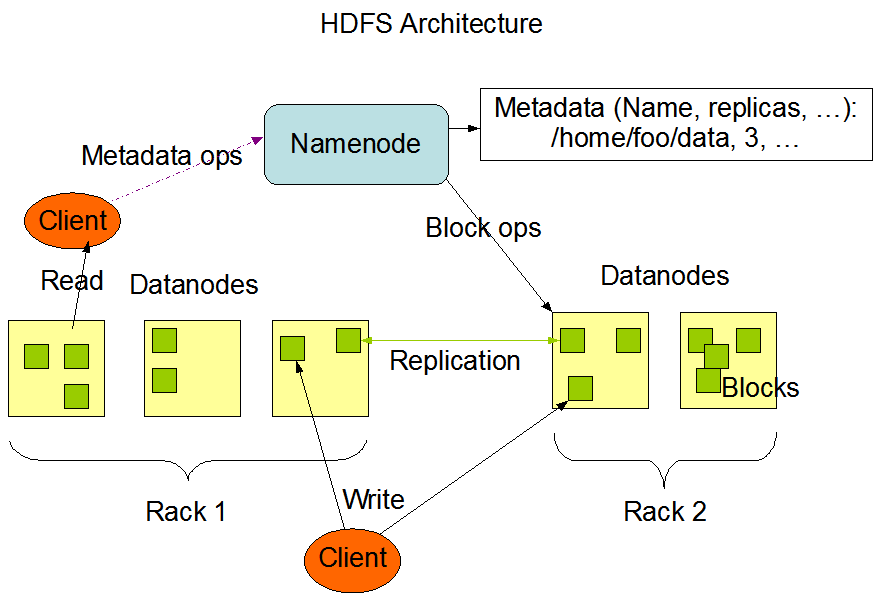
Data Storage
In HDFS, data is stored on DataNodes in the form of blocks. The storage process includes:
- Block Splitting – Large files are divided into fixed-size blocks (default: 128 MB) distributed across different nodes.
- Replica Placement – The default replication factor is 3. Typically, two replicas are stored on different nodes within the same rack, and the third on a different rack.
- Write Process – The client requests a write → the NameNode returns a list of DataNodes → the client writes blocks to the first DataNode, which then pipelines the data to others.
- Read Process – The client requests a read → the NameNode returns the list of DataNodes holding the blocks → the client reads from the closest DataNode.
Performance Optimizations
To support massive data storage and retrieval, HDFS implements several optimizations:
- Data Locality – Scheduling computation tasks to run on the same nodes that store the data, minimizing network transfer.
- Sequential Read/Write Optimization – Data is written sequentially, with block sizes planned to maximize throughput.
- Pipeline Replication – Data replicas are written in sequence across the DataNode list, improving write efficiency.
- Short-Circuit Local Reads – Local data can be read directly from the disk, bypassing the DataNode network stack, for faster access.
Limitations & Challenges
While HDFS is the distributed storage foundation of the Hadoop ecosystem, it has some limitations:
- Not Suitable for Many Small Files – Metadata is stored in the NameNode’s memory; too many small files will consume large amounts of memory while leaving DataNode disk space underutilized, wasting storage resources.
- No Low-Latency Random Access – Designed for batch processing, so real-time performance is poor.
- NameNode Scalability Limits – NameNode memory stores massive amounts of information to improve access performance, making scaling difficult. When a single NameNode reaches capacity, expansion can only be done via federation.
- Storage–Compute Separation – In cloud computing, object storage is increasingly replacing HDFS in some scenarios.
Conclusion
With its distributed, scalable, and fault-tolerant features, HDFS has become the cornerstone of big data storage.
However, it faces certain limitations. To address these, HDFS continues to evolve, adapting to new data processing needs.