Blogs
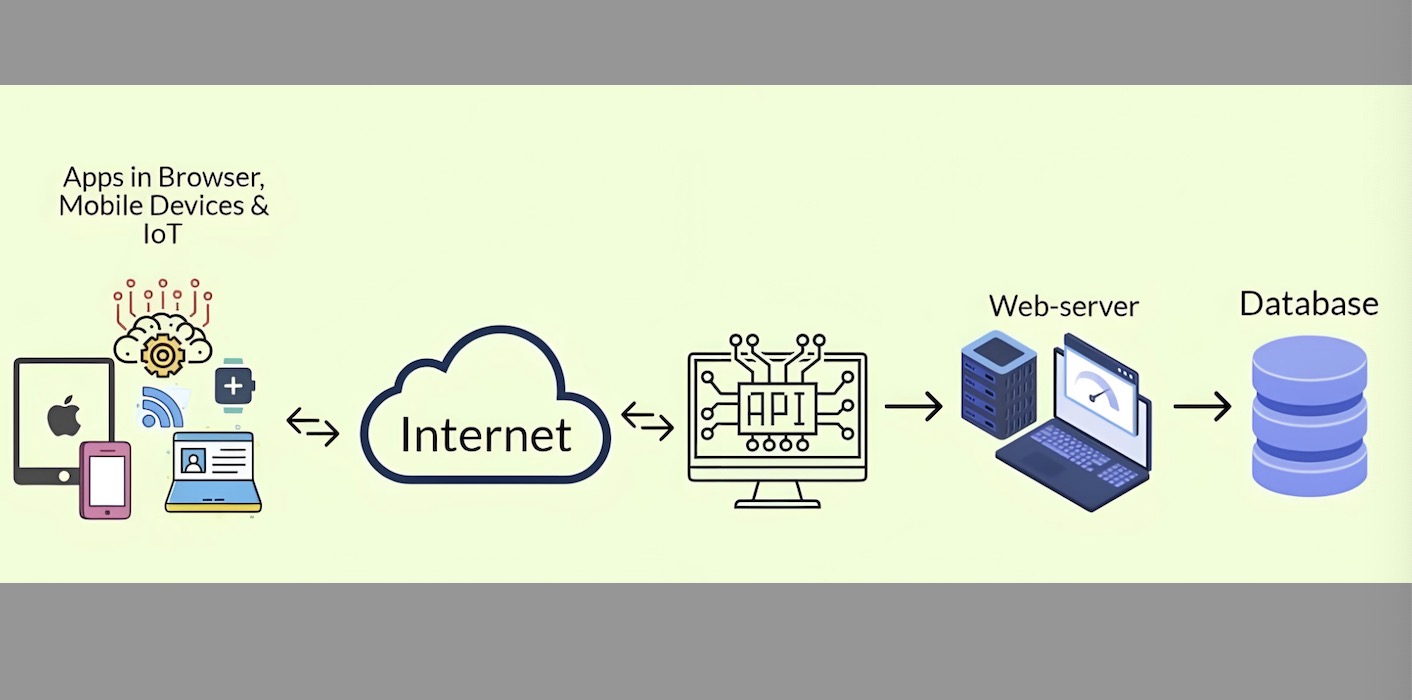
Our automated data collection solutions accommodate a variety of data sources, including websites, APIs, social media, and IoT devices, catering to the diverse needs of enterprises across different industries and scales