
A Web Scraping API is a production-ready interface for collecting structured data from websites at scale.
In the data-driven era, many teams need structured web data. Market research, software development, and SEO analysis all rely on it. Efficient data collection has become a core requirement.
Traditional web scraping requires significant effort to address issues such as IP bans, CAPTCHA solving, and dynamic rendering. However, the emergence of Web Scraping API has completely simplified this process.
As a comprehensive Web Scraping API pillar guide, this article explains definitions, core principles, tools, tutorials, and compliance guidelines.Learn more about cost control strategies for production scraping systems.
It helps you efficiently master data collection while aligning with search engine retrieval logic to quickly find the answers you need.

This guide serves as a central pillar page for web scraping API.
It covers how a web scraping API works, its use cases, advantages, selection criteria, and compliance best practices.
What Is a Web Scraping API? What This Guide Covers?
- What a web scraping API is and how it works
- Web scraping API vs self-built crawlers
- Web scraping API use cases across SEO, market research, and AI
- Key advantages and limitations of a web scraping API
- How to choose the right web scraping API
- Compliance best practices
I.How Does a Web Scraping APIs Work?
Third-party providers offer a Web Scraping API as a standardized interface that bundles web scraping, anti-scraping handling, and data parsing.
Developers can obtain structured data such as JSON or CSV through simple API calls, without building and maintaining a full crawler architecture.
For developers building production scraping systems, understanding HTTP for Web Crawling is essential. It covers request methods, status code handling, and best practices for stable communication with target websites.
1.1 Core Working Flow of a Web Scraping APIs
The working logic of a Web Scraping API is clear and easy to understand, consisting of 5 core steps that adapt to various complex scraping scenarios:
- Initiate a Request: Users send a request to the API service provider via code or tools.
The request includes the target URL, data parsing rules, and parameters such as region or language. - Anti-Scraping Handling: After receiving the request, the API server rotates IPs using a built-in high-anonymity proxy pool and simulates real browser fingerprints such as User-Agent and cookies.
At the same time, it handles anti-scraping mechanisms including CAPTCHAs and JavaScript-rendered content.
Large-scale scraping systems rely heavily on proxy infrastructure to avoid IP bans and distribute requests across multiple addresses.
A detailed explanation of HTTP proxies, SOCKS5 proxies, and proxy pool architectures can be found in our guide on Proxy Infrastructure for Web Scraping.
To understand the underlying mechanisms like proxies, user-agent spoofing, and dynamic content handling, refer to our detailed guide on HTTP protocol fundamentals. - Web Scraping: Access the target website through compliant methods to retrieve the original HTML code.
The scraping process respects the target server’s load requirements. - Data Parsing: Extract valid data from the original HTML based on user-specified rules or the API’s default parsing logic.
The system removes redundant information and converts the data into a structured format. - Return Results: Feed back the parsed structured data to the user, who can directly use it for data analysis, project development, content aggregation, and other scenarios.
For a hands-on example showing how these steps are implemented in code, check out our tutorial on Playwright web scraping for dynamic content.Dynamic rendering guide (Google).
1.2 Web Scraping API vs Self-Built Crawlers

Many people wonder, “Why choose a Web Scraping API instead of building your own crawler?” The core differences lie in development costs, stability, and maintenance efficiency. The following table clearly compares the core dimensions of the two:
| Comparison Dimension | Traditional Self-Built Crawler | Web Scraping API |
| Development Cost | High: Requires crawler expertise, anti-bot handling, and proxy management | Low: Basic API calls only, quick setup in minutes |
| Stability | Lower: Breaks when anti-bot rules change, requires manual fixes | Higher: Auto-adapts to site changes with 99%+ uptime |
| Maintenance Cost | High: Needs dedicated staff for IP bans and CAPTCHA handling | Low: Provider handles maintenance and updates automatically |
| Scraping Efficiency | Limited: Small proxy pools limit concurrency and scraping speed | High concurrency: Distributed nodes and large proxy pools boost speed |
| Use Cases | Simple scenarios: Static sites, weak anti-bot, small data volumes | Complex scenarios: E-commerce, search engines, social media, strong anti-bot |
If you want to understand how crawler architecture differs from API-based scraping systems, read our complete guide to web crawler technology.To control production costs when using a Web Scraping API at scale, see our Web Scraping API cost control guide.
II. Web Scraping API Use Cases
2.1 SEO Optimization & Full-Cycle Monitoring
This is the most mainstream and core use case of SerpAPI, targeting SEO practitioners, digital marketing teams, and enterprise brand operators:
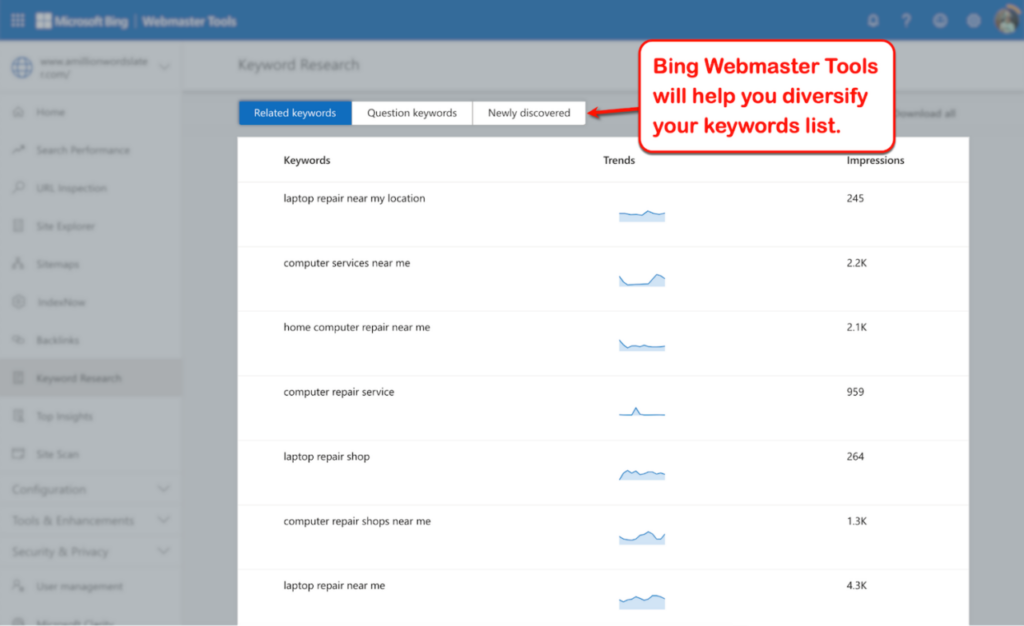
- Keyword Ranking Tracking: Batch monitor the organic rankings and ad rankings of target keywords on search engines such as Google, Baidu, and Bing. Support filtering by region (e.g., a specific city/country), device (mobile/desktop), and language. Real-time grasp of keyword ranking fluctuations to evaluate the effectiveness of SEO optimization strategies (e.g., content updates, backlink building).
- Competitor SEO Analysis: Scrape competitors’ website keyword ranking distributions, SERP placement types (e.g., organic results, knowledge panels, video results), and page indexing status. Identify competitors’ core traffic-driving keywords and optimization gaps to adjust your own SEO layout.
- SERP Feature Monitoring: Track changes in SERP features related to target keywords, such as ad slots, Local Packs, Q&A boxes, and image carousels.
These features affect organic ranking exposure and help guide page format optimization, such as creating targeted Q&A content. - Domain Authority Auxiliary Analysis: Combine domain name display frequency and ranking stability in SERP data to assist in judging a domain’s authority in search engines, providing data support for domain name selection and site cluster layout.
2.2 Market Research & Competitor Business Analysis
Targeting product managers, market researchers, e-commerce operators, and enterprise strategic planning teams, leveraging search engine result data to identify market opportunities:
- Product Price & Competitor Monitoring: Scrape product display information, price ranges, and promotional activities of e-commerce platforms (e.g., Amazon, eBay) in search results, or official website pricing and functional selling points of industry competitors. Quickly grasp the market price system and competitors’ core advantages.

- Industry Trend Insight: You can scrape changes in the search popularity of long-tail keywords and related search suggestions.SerpAPI can return search engines’ “related searches” and “people also search for” data.By analyzing this data, you can identify potential user needs and predict industry trends. For example, you may detect upgrades in product feature requirements or rising demand in certain regional markets.
- Brand Reputation Monitoring: Search for brand names and related negative keywords, scrape news reports, social media reviews, and Q&A platform feedback in SERPs. Real-time monitor the exposure and spread path of negative brand information, and promptly launch public opinion response plans.
For practical insights into analyzing competitor search rankings and pricing strategies, see our example on Amazon competitor data extraction.For e-commerce–specific scraping tasks such as price monitoring, review scraping, and inventory tracking, explore our Ecommerce crawler API guide.
2.3 LLM (Large Language Model) Integration with Real-Time Search

- The core idea of integrating search results with LLMs is to equip large models with the ability to obtain external information in real time, solving the problem of outdated model knowledge and making their responses more accurate and timely.
- Enable AI to possess “real-time data perception + precise decision-making capabilities” and address the “outdated knowledge” issue of LLMs.
Traditional LLMs only learn from training data up to a fixed cutoff (e.g., GPT-4 in October 2023) and cannot access the latest information, such as 2024 industry trends, real-time stock prices, or current competitor dynamics. - SerpAPI can scrape the latest search engine results, such as daily news, real-time rankings, and the latest prices.You can then feed this data to LLMs. This allows them to gain real-time data perception capabilities.As a result, they can produce outputs that better match current scenarios. For example, they can support real-time market analysis or interpret the latest policies.
For specific strategies on using Web Scraping APIs to collect, clean, and manage AI training data, see our Web Scraping API for AI training data guide.
2.4 Local Business Optimization
Targeting local stores, chain brands, and local lifestyle service platforms (e.g., catering, medical aesthetics, housekeeping), focusing on Local SEO (Local Search Engine Optimization):
- Local Ranking Monitoring: Track Local Pack rankings, map marker positions, merchant ratings, and review counts for “city + service” keywords (e.g., “Beijing Chaoyang District coffee shop hopping”, “Shanghai Pudong housekeeping services”). Grasp local users’ access entry points.
- Local Competitor Analysis: Scrape local SERP display information, user review tags, and service scopes of competitors in the same city. Adjust your own store’s online information (e.g., optimization of Dianping and Baidu Maps merchant information) and offline service strategies.
- Local Demand Mining:Use regionalized keyword SERP data to identify the personalized needs of local users.For example, users in a certain area may focus more on “cost-effectiveness” or “24-hour service.”You can then optimize store services and promotional copy based on these insights.
2.5 Data Science & Business Intelligence (BI) Construction
Targeting data analysts, data scientists, and enterprise BI teams, providing structured data sources for data modeling and decision support:
- Structured SERP Data Collection: SerpAPI directly returns structured data in JSON/XML formats (e.g., rankings, titles, links, summaries, image URLs), eliminating the need for developers to parse HTML pages themselves. It can be quickly integrated with data warehouses and BI tools (e.g., Tableau, Power BI).
- User Search Behavior Analysis: Integrate SERP data from multiple regions, time periods, and devices to analyze search preferences of different user groups (e.g., mobile users pay more attention to local services, young groups focus on trending keywords). Provide data model support for product design and marketing campaigns.
- Industry Data Dashboard Construction: Build industry-wide SERP data visualization dashboards to real-time monitor industry keyword rankings, competitor dynamics, and changes in market demand, providing data references for senior enterprise decision-making.
2.6 Automated Business System Construction (Avoid Anti-Scraping Costs)
Targeting developers and technical teams, used to build automated business systems dependent on search engine data. The core value is eliminating the anti-scraping maintenance costs of self-built crawlers:
- Recruitment/Real Estate/Second-Hand Information Aggregation: Scrape recruitment information (e.g., SERP displays from Zhaopin and BOSS Zhipin), real estate listings (e.g., listing information from Lianjia and Beike), and second-hand product information from search engines. Build information aggregation platforms without handling anti-scraping mechanisms of various platforms independently.
- Automated Ad Campaign Performance Monitoring: Integrate with ad delivery systems to automatically scrape SERP rankings and exposure positions of ad keywords. Compare ad delivery costs with ranking effects to realize automated adjustments of delivery strategies.
- Academic/Literature/News Aggregation: Scrape paper search results from Google Scholar and Baidu Scholar, or news content from news search engines. Build vertical domain news aggregation platforms to quickly obtain structured academic/news data.
For search engine data collection at scale, you may also want to explore how a production-ready SERP API works in real-world environments.For deeper insights into choosing the right provider for different production scenarios, refer to our Web Scraping API vendor comparison.
III. Key Advantages of a Web Scraping API
Web Scraping APIs have rapidly replaced traditional self-built crawlers.
Enterprises and developers now prefer them.
This shift mainly comes from their advantages in efficiency, stability, and compliance.
Specifically, they can be summarized into 6 core values:
3.1 Lower Technical Threshold, Accessible to Beginners
No need to master complex technologies such as Python crawler frameworks (e.g., Scrapy), JavaScript dynamic rendering handling (e.g., Selenium), or CAPTCHA recognition algorithms. Only basic API call logic (e.g., sending requests using the Requests library) needs to be understood to complete data collection. Even users with zero foundation can quickly implement their needs by referring to the documentation provided by service providers.
3.2 Strong Anti-Scraping Capabilities, Avoid IP Ban Risks
Mainstream Web Scraping API service providers are equipped with tens of millions of high-anonymity proxy pools covering multiple regions worldwide.
They can automatically switch IP addresses and browser fingerprints. This helps avoid issues such as IP bans and account restrictions from target websites.
For complex CAPTCHAs, such as Google reCAPTCHA or SMS CAPTCHAs, the API includes a built-in intelligent recognition engine. It can complete verification without manual intervention.
3.3 Support for Dynamic Web Pages & High-Concurrency Scraping
Many websites built with Vue and React load content dynamically via JavaScript, which traditional crawlers struggle to handle. Web Scraping APIs solve this by using headless browsers like Chrome Headless to render pages and extract full content.
Additionally, they support high-concurrency requests to meet large-scale data collection needs (e.g., scraping full-category product data from e-commerce platforms).
3.4 Real-Time Adaptation to Website Updates, Ensure Data Continuity
The HTML structure and anti-scraping rules of target websites may be updated at any time. Traditional crawlers require manual code modifications to resume use.
Web Scraping API service providers assign professional teams to monitor changes on popular websites in real time.
They automatically adjust scraping strategies and parsing rules. This ensures that data collection is not affected.
It also guarantees the continuity of business data.
3.5 Structured Data Output, Reduce Parsing Costs
APIs usually return standardized data formats such as JSON and CSV.
Users can directly import this data into Excel, Python Pandas, or databases like MySQL for analysis.
They do not need to manually parse HTML with tools such as BeautifulSoup.
This significantly reduces data processing time.
IV. How to Choose a Web Scraping API
When selecting a Web Scraping API, it is necessary to focus on the following 6 core dimensions based on your own needs (scenarios, budget, technical level) to avoid blind selection:
4.1 Scenario Matching
First, clarify your scraping scenario. When it comes to search engine scraping, SerpAPI is usually the best choice.
For dynamic web pages, especially those rendered with JavaScript, ScrapingBee performs better.
In high-difficulty anti-scraping scenarios such as e-commerce platforms or social media sites, BrightData is generally more suitable.
Meanwhile, ParseHub is ideal for users with zero technical background, thanks to its no-code interface.
4.2 Stability & Availability
Check the service provider’s availability commitment (e.g., 99.9% uptime) and user reviews (refer to platforms such as Trustpilot and G2). Prioritize service providers with a good industry reputation and professional operation and maintenance teams to avoid business disruptions due to API failures.
4.3 Proxy Pool Quality
The proxy pool is the core competitiveness of a Web Scraping API. Focus on the number of proxies, coverage regions, IP types (Residential IPs are harder to be banned than data center IPs), and whether automatic IP switching is supported.
4.4 Price Cost
Choose packages according to your request volume. Free or low-cost plans (e.g., SerpAPI $50/month) suit individual developers and small projects, while enterprise-scale scraping usually requires customized packages. Pay-as-you-go options can further improve cost-effectiveness.
4.5 Technical Support
Prioritize service providers that offer detailed documentation, sample code, and 24/7 customer support. Especially for beginners, technical support can significantly reduce the learning curve and avoid project delays due to unresolved issues.
V. Web Scraping API Compliance and Best Practices
Compliance in data collection is a core prerequisite. Combining industry norms and legal requirements, the following 4 key points are summarized to help you avoid risks:
5.1 Comply with the robots.txt Protocol
The robots.txt file in the root directory of the target website (e.g., https://www.yahoo.com/robots.txt) clearly indicates which content can be scraped and which cannot. Web Scraping APIs usually automatically comply with this protocol, but users should confirm in advance to avoid scraping prohibited content.
5.2 Control Scraping Frequency
Avoid high-frequency requests to target websites to prevent excessive server load or even legal risks. Most APIs default to limiting request frequency. Users can adjust it according to their own needs or contact the service provider to customize a reasonable scraping rhythm.
5.3 Standardize Data Usage
Scraped data should only be used for legitimate purposes (e.g., personal learning, internal enterprise research). Do not infringe on others’ copyrights or privacy rights (e.g., scraping user personal information, trade secrets). It is prohibited to use scraped data for illegal profit-making, malicious competition, or other activities.
5.4 Avoid Scraping Sensitive Content
You must not scrape restricted data from sensitive fields such as government websites, financial institutions, and medical platforms. You must obtain authorization from relevant departments to collect such data; otherwise, you may incur severe legal liabilities.
VI. Web Scraping API FAQ
The following answers 6 of the most commonly asked questions by users, covering core doubts about technology, cost, and compliance:
Q1: Is a free Web Scraping API sufficient?
It is suitable for personal learning and small projects (monthly requests ≤ 1000 times). Free versions usually limit the number of requests and features (e.g., no support for dynamic rendering). For commercial scenarios, it is recommended to choose a paid version to ensure stability and full functionality.
Q2: Can a Web Scraping API scrape all websites?
No. Some websites adopt extremely strong anti-scraping technologies (e.g., blockchain verification, manual review) or explicitly prohibit any form of scraping, which even top-tier APIs cannot bypass. It is recommended to confirm the target website’s scraping policy in advance.
Q3: Can I use a Web Scraping API without coding?
Yes. Some service providers (e.g., ParseHub, Apify) offer visual operation interfaces. You can configure scraping rules by dragging and clicking, so users with zero foundation can use it without coding.
Q4: How fast is the scraping speed of a Web Scraping API?
It depends on the service provider’s node distribution, proxy pool quality, and request concurrency.
In ordinary scenarios, the response time for a single request is within 3 seconds.
In high-concurrency scenarios, the system can process 10–100 requests per second to support large-scale data collection.
Q5: Can the scraped data be used for commercial purposes?
It depends on the situation.
You can collect public, non-confidential data, such as product prices on e-commerce platforms.
Its use for commercial purposes requires authorization from the target website.
However, using copyrighted content or trade secrets requires permission from the rights holder, otherwise it may constitute infringement.
Q6: How to judge the stability of a Web Scraping API?
Three methods can be used:
Refer to industry evaluations and user cases, prioritizing providers with large enterprise partnerships.
Check the service provider’s availability commitment.
Monitor the API’s response success rate during the trial period.
Related Web Scraping Guides
This article is part of a broader Web Scraping API topic cluster.
You may also find the following guides useful:
- Proxy for Web Scraping: What It Really Means
- Understanding HTTP Proxies: Your “Delivery Guy” on the Internet
- Understanding SOCKS5 Proxies: How They Work and When to Use Them
- TLS Fingerprinting Explained: From HTTPS Security to Bot Detection
- Real-Time Price Monitoring UnderAdvanced Anti-Scraping Systems
- Playwright Web Scraping in Node.js: Render Pages, Extract Data, and Store Results
- Mitmproxy For Web Scraping: in Intercept, Clean, and Store HTTP Data
- Building a Proxy Pool: Crawler Proxy Pool
- Crawling HTML Pages: Python Web Scrawler Tutorial
- Web Crawling & Data Collection Basics Guide
- SERP API Production Best Practices
- Generative Engine Optimization (GEO): The Transition from SEO to AI Search
VII. Summary
By encapsulating complex technologies, Web Scraping API offer an all-in-one solution that significantly lowers the barrier to web data collection for enterprises, developers, and SEO practitioners.
Their core value lies in “allowing users to focus on data application rather than technical implementation”. Whether for market research, SEO analysis, content aggregation, or project development, they can significantly improve efficiency.
In the future, with the integration of AI technology, Web Scraping API will enable more intelligent functions such as automatic page structure recognition, optimized scraping strategies, and real-time data anomaly alerts.
Choosing a Web Scraping API that suits your own needs will become an important competitive advantage in the data-driven era.
For production scenarios specifically focused on search engine results and automated monitoring, our SERP API production best practices guide provides practical strategies.